

Creative AI tools have gone mainstream. Have they lost their primitive, often disturbing but powerful soul?
Once upon a time the world was a realm of unanswered questions and there was room in it for poetry. Man stood beneath the sky and he asked “why?”. And his question was beautiful.
The new world will be a place of answers and no questions, because the only questions left will be answered by computers, because only computers will know what to ask.
Perhaps that is the way it has to be.
James Cameron, 1969
Looking back from today, it’s impressive how far the creative AI toolchain has gone in a small amount of time, evolving from a nerdy toy to a mainstream soon-to-be commercial technique.
The feeling I’m currently gathering from people entertained by creative AI experiments is that they look for results that perfectly meet their expectations, being surprised by strange or unforeseen behaviours. Some time ago the situation was reversed: people were amazed when something kind-of-well-defined came out, but they were basically waiting for unexpected discoveries, astonishment, and inspiration.
This reflects the transition between experimental and commercial.
These days I re-developed with the currently available tools an experiment I carried out 2 years ago. Comparing the results is just an excuse to unleash a flow of thoughts about creativity and art.
2 years ago
For I MILLE, the studio I work at, 2 years ago I crafted an AI experiment called “fAInding beauty”: the idea was to ask an AI to write an issue of “Finding beauty”, the newsletter curated by my former colleague Antonio Di Battista showcasing a weekly top 5 about creativity.
To craft “fAInding beauty” issue 44 I had to scrape 4 Twitter accounts and 2 Instagram hashtags, collect, clean, and prepare thousands of lines of text and thousands of images, and finally feed them into a tool called Runway to custom train two models. Nothing super complex, but accessible only to someone with a decent technical background and some familiarity with coding, and needing an effort of at least a couple of days.
We selected 5 artificial tweets generated by a GPT-2 model trained with all the tweets by @itsnicethat, @Artforum, @CreativeReview and @designboom, and we associated each tweet with an artificially generated image: 4 images created using a prebuilt tool, and the last one training a StyleGAN with a set of images collected by the Instagram hashtags #erotic and #taekwondo (directly related to the chosen tweet).
Here’s the full result.
And here’s the issue cover image, related to our favourite tweet “#erotic café de vivre in Paris by #taekwondo pro is absolutely genius”.

I absolutely love it, because it embodies the magic side of the childhood of AI image generation: something coming straight from the depths of apparent randomness but laterally and surprisingly on topic, representing the input in consistent yet unexpected ways, opening extra associations, feelings, and “doors”.
This image feels to me very Man Ray, perfectly rendering the bizarre and avant-garde atmosphere of an erotic café “de vivre” in Paris. At the same time, even if there’s nothing explicitly connected with taekwondo, it retraces the weirdness of the association between the first and the second part of the tweet.
A lot of images have been output by the algorithm: many of them quite confused and rudimentary, others poorly related to the tweet’s topics, and some ones interesting. But none of them as effective as the one I chose.


Today
What about doing the same experiment today? It’s a 5-minute job. This is the output I got feeding with the same tweet to the three most popular image generation tools Midjourney, DALL·E and Stable Diffusion:
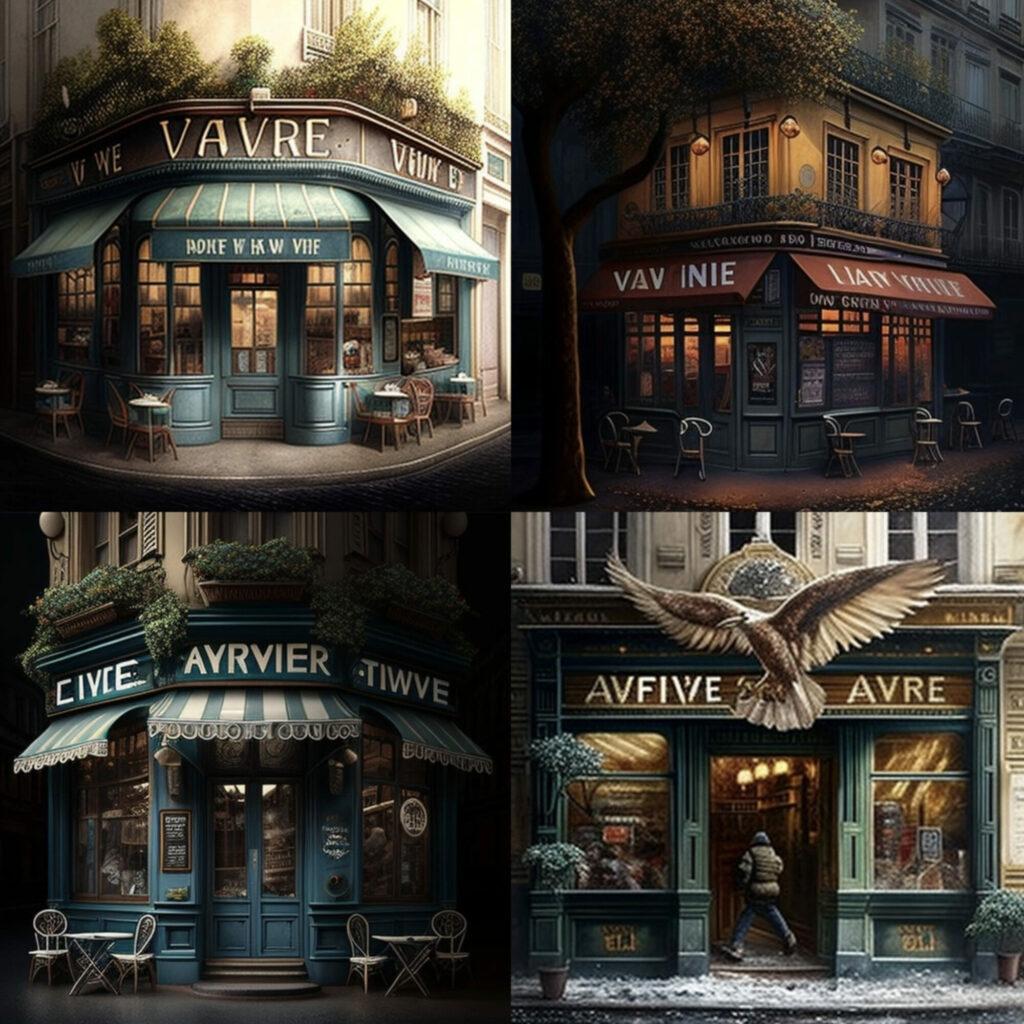


To me, not really exciting.
Much more refined and realistic results than the ones generated two years ago, but also more standard and less intriguing.
I have to say that today I took just the first outputs, while before I carefully selected a few images among a collection of 500, most of which not too far from noise. But —apart from this— the look and feel is clearly different: while the old images were quirky, experimental, and artisanal, yet quite powerful and expressive, today’s are just very descriptive and straightforward, without any real grasp of the prompt’s oddity.
DALL·E’s results are the least interesting: while Midjourney and Stable Diffusion tried to put some personality and “French feel” into the outputs, DALL·E’s images are very generic and unoriginal — a far cry from its namesake.
So what?
Today it’s very simple for almost everyone to access and use artificial image generation techniques, but the results are pretty standard and flat in terms of creativity —if a human doesn’t actively spice up things.
There are precise reasons for that:
→ today’s tools are a lot more advanced in size and speed: the current neural network architectures have a lot more elements, layers and parameters compared to the old ones. Nevertheless, given the same amount of time spent for calculations, they could process much more data in both training and generation modes thanks to software optimisations and hardware scale-ups.
Since they have been trained on massive datasets (billions of images), they can very often come up with consistent outputs for pretty much any input prompt without a dedicated training, and for the same reason (their knowledge has been built upon an average of everything) the interpretation is quite generic and straightforward.
In other words, we get blurry jpegs of the web (the linked article is talking about chatGPT, but the concept applies to image generation as well).
→ today’s tools rely on diffusion algorithms, while 2 years ago they usually used a GAN architecture. GAN architectures are based on two networks working against each other: one produces an output and the other one decides if it’s is good enough, giving a feedback about how far from desired the result is . Because of this contrast, it’s often difficult to achieve a good balance, tuning the skill of the generating network and the strictness of the judging one. Diffusion algorithms are easier to train and to calibrate, and more keen on producing outputs without glitches and side effects (see the paper “Diffusion Models Beat GANs on Image Synthesis”).
By the way, it’s very interesting to notice that GAN and Stable Diffusion algorithms work with mirrored philosophies: GAN starts from noise and progressively builds something up with the aid of a trained network, while Stable Diffusion pollutes the training data, reduces them to noise and then trains a network to reverse the corruption process. Amazing, isn’t it?
If you’d like to go deeper, here are two interesting articles about the birth of the GAN concept and the mechanisms underlying diffusion models.
So, I can say that using the old tools was like asking a kid to draw something—with little experience and poor technique but a lot of fantasy. While, running the current ones in “default mode” is like working with a trained student with good execution skills and with the capability to deal with any style and subject, but without any passion and soul.
If you want passion and soul, you (the user) must try to inject them in the process.
Yesterday the creativity was embedded in the process while today it’s more in the final user’s hands.
With this in mind, I tried to use the Man Ray inspiration given by the old experiment to add a twist to the new one. Here are the results running this prompt: “café de vivre in Paris by taekwondo pro is absolutely genius, in the style of a Man Ray photograph”:



They start to become more interesting, aren’t they?
Stable Diffusion still gives the most interesting results (I love the last image), while Midjourney didn’t change much, just rendering its dramatic feel in black and white. DALL·E is the most surprising, switching from super generic representations to very avant-garde ones, in four different styles (ranging from Depero-esque to contemporary social advertising).
Looking at the surface of things it seems that in two years everything changed, but from a true creative perspective I think we haven’t gone so far.
Being trained on pretty much everything existing, the new tools are able to generate quite easily something average, but to come up with something more specific and creative a huge contribution of a human is needed: carving carefully the prompts, performing a custom training on the algorithm, or even repurposing the algorithm itself.
On the other hand, the old tools were dirty and noisy, with sometimes very surprising and original outputs but very often with a specific look and feel: unfinished, distorted, gloomy, and unsettling.
For example, many creations of the first era looks very Francis Bacon: uncanny, distorted, blurred, and dribbled. It’s one of the trademarks of GANs. I personally love this style, but —considering the scale of the topic — it’s a limitation.
If we go back even earlier (2015), we can see another example of medium being the message (in this case the algorithm is the medium): DeepDream convolutional neural networks, finding and enhancing patterns in images via algorithmic pareidolia, created deliberately over-processed outputs.

In the end, in this early stage of experiments, the styling was more connected to the algorithm than to the system training or the input.
Conclusion
During the late Renaissance, critics thought that Leonardo, Michelangelo, Tiziano, and Raffaello reached definitive perfection: for this reason, many artists of the XVI Century painted following the style of those masters rather than taking nature as a model, in many cases creating sterile repetitions of the forms of others.
This trend, called Mannerism (Manner = style of the masters), was blamed for centuries: because of the lack of originality and soul, but also for the alteration of poses and proportions applied by some artists to push the traditional style further, that were seen as meaningless virtuosities and artificial exaggerations.
And it’s precisely for this latter characteristic that later, in the early twentieth century, the judgment of the movement witnessed a change of course: the anti-classical components started to be highlighted rather than disapproved, stating their extraordinary modernity, understood as a way to express and convey emotions that anticipated the avant-gardes of the 20th century.


From a purpose of total conformity, the Mannerist era became in fact a forge of personal interpretations and deviations, leading to visionary results. As an example, from composition to color usage, the “twin” Depositions by Rosso Fiorentino and Pontormo show many elements completely out-of-their-time’s canons.
The artist embodying more than any other the disrupting side of Mannerism is Domḗnikos Theotokópoulos, most widely known as El Greco: his works, especially the latest ones, look ahead by at least three centuries. I wonder about the shocked reactions of his contemporaries when looking at those unworldly, dissolving figures, trembling in an unreal upsetting light: people used to seeing more and more accurate representation of reality, being instead fully exposed to the deepest portrayal of the artist’s soul.
In both early-stage and last-generation artificial image synthesis, I see a sort of Manner (the original conception of it), whether it be the gloomy and unfinished early GAN style, the possibility to mimic many existing ones or the average representations supplied by today’s diffusion models.
Some years ago the Manner was essentially related to technical limitations: the surprising and bizarre feel of the outputs was related to the GAN’s difficulty to be calibrated and balanced, while the custom training of the models acted mainly on the choice and rendering of the created subjects.
Conversely, now we have the opportunity to match our technical and creative skills to train and tweak more performant models, which are able to better follow our emotions and ideas and to come up with novel subjects and styles.
As is the Mannerist trend, born as conformity and evolved into inconceivable freedom, I wish for the new technical and creative developments to enable possibilities for people to break free from the canons, fostering exploration, research, and discovery.
I wish for people to use these magical and incredibly powerful tools to go wild, just as the Mannerists did, instead of easing down and replicating existing styles and subjects.
In general, it became much harder to generate strange, uncanny, surreal, not correct images in Midjourney after v 4.
Lev Manovich, (10 May 2023)
Despite this sentence by Lev Manovich, one of the main voices in the field of digital culture and new media, my DeepDream for the future is an injection of advanced techniques and great human creativity into more and more performant tools, overcoming the limitations of the old techniques while preserving their experimental and surprising breath.
So, guys and girls playing with AI, don’t be bewitched by its apprentice level ease: study, explore, try, fail, dream, despair, try again, discover, and always try to find your way.
Stay wild, stay El Greco!

